Cloud Application Infrastructure from Code (IfC)
The Next Logical Step in Cloud Automation
This is a technical sequel to an IDG Connect article that presented a relatively new concept of Infrastructure from Code (IfC) as the next logical step in cloud automation. IfC, at its core, refers to the fully automated generation of cloud configuration specifications based on the interpretation of application code. It builds on the widespread adoption of Infrastructure as Code (IaC), which to date requires manual generation and maintenance of cloud configuration specifications. This article aims at providing a more formalized justification for the assertion that IfC is the logical successor to IaC and will evolve quickly.
To understand why traditional Infrastructure as Code is no longer adequate for the new serverless world, we need to return to the very basics. Since the topic is vast and the amount of available material, tools, and solutions is large, opinions differ widely on exactly what IaC includes and where it is headed. First, we need to agree on a deductive methodology and structural analysis of the technology available today then proceed to the most plausible scenarios for future evolvement — and the needs or constraints emerging from it.
In this publication, I intend to come up with a coherent and not-so-complicated train of thought suitable to serve as a conceptual foundation for the practical work ahead. The article’s flow is as follows:
- Conceptual Framework
- Technological Evolution
- Cloud Infrastructure as Code Stack
- Addressing IaC Challenges
- Infrastructure from Code Needs
- The New Wave of IfC
Conceptual Framework
Principle: Technology and Practices Evolve Together
Technology never stays still. Whenever something new and useful is introduced, it shortly thereafter embarks on the process of commoditization. More and more people learn to do it with higher efficiency. Commoditized and standardized technological capabilities beget new technology innovations [1].
Technology and practices co-evolve [2]. New technology renders some practices obsolete (muleteers are less in demand today) and creates a need for others (truck drivers are essential, at least until now). While randomness and sheer lack play a significant role in the co-evolution of technology and practices, it is unlikely for things to arbitrarily jump from one point to another. Some things are more likely to happen than others. Using a bit more formal language, we may argue that technology’s and practices’ co-evolution constitutes a Semantic Spacetime [3] fabric.
Context: DevOpsFinSec — It’s not what you think!
The DevOpsFinSec concept is often confused with writing and maintaining automation scripts for infrastructure resource allocation. At times, it is also linked to monitoring. At least, this is what is meant in the hiring advertisements for DevOps Engineers.
This is a narrow view of the subject matter and contradicts the original definition of DevOps. As explained by Patrick Debois, who coined the term, DevOps is “to bridge the gap between developers, operations and sysadmins in an Agile way.”
I think this diagram [4] best explains the whole concept of DevOps (Recommended: print this on A3 and stick it on your board in front of you). In this model of DevOps, there are four key areas of interaction (knowledge exchange and feedback) between dev and ops.

If we dig a bit deeper into Patrick’s article, we find another interesting diagram that describes the layers at which the interaction happens.

What do we learn from these two diagrams? That DevOps (or more expansively DevOpsFinSec) approach assumes four types of cooperation between the disciplines involved in delivering software services to end users: two of which originate from development and two from operations. Each area requires tools for automation, processes (preferably lite ones), and people with an open mindset.
Here, I want to make it abundantly clear that without human cooperation across multiple disciplines, no tool or process can help.
Disorder + Automation = Automated Disorder
Motivation: Infrastructure as Code
Now, Infrastructure as Code (IaC) can be defined more accurately as a set of tools for automated infrastructure resource allocation (Area I: Extend delivery to production; Area 3: Embed project knowledge into operation). Notice, by itself, IaC does not talk about observability (Area 2: Extend operations feedback to project) and automatic adjustment (Area 3: Embed operations knowledge into the project). Though, it does take part in instrumentation for monitoring or alerting and implicitly takes into account the operation specifics and requirements in automation scripts.
Although these distinctions are widely adopted for multiple reasons, they are far from precise. In 1993, Mark Burgess created the pioneering CFEngine system, which covers all aspects of automation, influenced almost every IaC tool in the market today, and is still unsurpassed. Space constraints of this article do not allow for going deeper into the CFEngine theoretical foundations and practical solutions. I highly recommend watching the “Beyond Automation with CFEngine 3 series of lectures on O’Reilly.
To sum up this preliminary analysis, IaC is about creating executable documents, which describe computer resource allocation and resource interconnection aiming at a particular goal.
Technological Evolution: how did we get here?
As mentioned above, technology, tools, and practices co-evolve, but they do not move completely arbitrary. Some forces determine the probability of the move. Some things are easier than others, and like water, things move towards the lowest possible energy expenditure.
In the context of automation in general and IaC in particular, the key driving forces are:
- number of computers to manage
- the power of individual computers and scale-up vs. scale-out preferences
- speed and reliability of the network
- number of applications and services to deliver
- frequency of software releases
- number of end-users to serve
- latency and availability expectations
These factors influence each other. As spacetime and matter influence each other (thank you, Mr. Einstein), evolution and innovation, capabilities and needs beget each other.
Let’s see how this dynamic works in the IaC space.
It all started with bare-metal data centers
In the beginning, in the 1990s, the number of computers per typical data center was small, networks were still relatively slow and unreliable, only scale-up preferences prevailed, the number of applications and services was not too big, and the updates were released relatively infrequently.
In such an environment, manual cobbling together of the components by skillful system engineers was a norm. I started working for such a company in 1995. The company management was convinced that paying a high salary to a bunch of experienced system engineers would cost less than developing a highly automated delivery system which would distract the best talents from the company’s core business (in that case, conditional access to Pay TV). Of course, these system engineers only used some basic installation scripts and nothing more.
On the other hand, a trend emerged with the new generation of web applications and services (Google, eBay, Amazon, and Facebook to name a few) where companies preferred scaling out, needed a larger number of computers and software components to manage and a higher frequency of updates. For them, the smart system engineering cowboys pattern did not work. Still, managing physical compute, storage, network boxes on an organization’s data centers was a norm.
In 1993, CFEngine was introduced to address the challenges posed by large-scale data center management. From the very beginning, there was a need to distinguish between:
- managing physical boxes (computers, storage disks, network switches, and routers)
- installing, patching, and upgrading basic system software (operating systems, database, or messaging servers)
- installing, patching, upgrading, and removing applications and custom services
Following CFEngine, many tools addressing different aspects of these problems were introduced with different degrees of success and popularity.
Since the whole process, although fully automated, was slow, expensive, and error-prone, the preference was to keep infrastructure resource allocation automation relatively decoupled from application development. For that purpose, a special term service density was coined to measure how many services or applications could run on the same underlying infrastructure.
And then came virtualization
With the introduction of virtualization (VMWare, etc.) at data centers, it was suddenly possible to significantly improve service density by reallocating physical boxes to different software needs. This publication is not a treatise on software industry history, so I won’t get into further details here. What is important to notice is that virtualization was a kind of lifting-and-shifting of bare-metal data centers into virtualized world. Conceptually, although, very few things changed.
Stairway to Infrastructure as a Service (IaaS) Heaven
With advances in Internet technology, renting out virtualized environments to be accessed over a network was the next logical step. It started from AWS S3 Storage and quickly expanded to other areas of compute and networking. Indeed, in many cases, it didn’t matter where is this virtualized environment physically located (pun intended). IaaS offerings promised less and less headache with managing physical boxes on-prem. But conceptually, IaC tools remained at the same level, lifting and shifting bare-metal data center configurations into the virtualized world.
Ironically, AWS S3 was probably the first cloud service, and from the very beginning, it was fully managed and serverless. Yet, with the introduction of the AWS EC2 service, the trend took a different route.
Let it be a Platform as a Service (PaaS)
Once we learned how to allocate basic virtual machines, attach them to storage devices and connect them via a network, it was quite natural to package a cluster of such resources running, say a database, and offer this resource bundle as a new service.
To support the new Platform as a Service offerings, existing IaC tools were extended to allow the specification of such a bundle. So, along with the specification of a virtual machine auto-scaling group, it was possible to ask for a MySQL database cluster. This packaging of high-level and low-level resources required was conceptually, still lifting-and-shifting bare-metal data center to the virtualized world.
With cloud-native architecture pioneered by Netflix and advances in container technology, such a simplified picture started to be less and less conforming to the original architectures and practices. Yet, very little changed at the conceptual level of IaC tools.
Serverless Cloud Tectonic Shift
And then came the serverless paradigm where developers did not have to bother about capacity. How did we get there? Quite simply, like in the physical world, as with technology evolution, proximity determines possible moves at any point in time. Autoscaling was prevalent in cloud computing services from the very beginning. It meant when the server load gets to a certain level, spin out another server; when it drops below a threshold level, kill one. But at the beginning, cloud users had to manually specify these numbers, and more often than not, they had no clue what these thresholds should be. It was only a matter of time before cloud vendors asked themselves if they could guess these numbers from the vast usage statistics they had collected over time.
A simple answer to the question, “Why the fuss about serverless?” and “how is it related to IaC?”, is that when infrastructure commoditizes, supporting tools and practices have to adjust accordingly. Currently, IaC leading tools and practices are seriously lagging behind.
Originally, IaC solutions were about creating executable documents capturing configuration of general-purpose infrastructure resources (physical or virtual compute, network, storage boxes) to serve an application(s) needs. Later, it was extended to support packaged platform services such as database clusters. But, conceptually, it remained the same.
Since the whole process, even when fully automated, was slow, expensive, and error-prone, the preference was to keep infrastructure resources allocation automation relatively decoupled from application development. (I intentionally repeat this sentence).
But, what if there are no low-level infrastructure resources like VM instances, disks, clusters, or routers to worry about anymore? True, you still need to allocate serverless or fully managed resources, but it is qualitatively different.
Are the same tools and practices still a perfect fit for the new environment? As S. Wardley argues in the article mentioned above, the answer is ‘No’. In a new environment, we need to think afresh and act anew. Indeed, Serverless affects design. But conceptually, IaC tools remained the same, only incorporated serverless resource specifications using the same bare-metal data center lift-and-shift language.
Manually crafting IaC templates is a tedious and error-prone process. For even a modest serverless cloud application, its IaC template can easily get to hundreds of lines of JSON or YAML. Another challenge is that the configurations can be confusing like, what is an AWS IAM Role, how is it different from IAM Policy, and how are these relevant if the application only needs to calculate the total number of vacations per employee per year?
Things do not stop here, though. While it is always critical to implement correct domain logic, for a real-time production deployment, there are additional concerns like if the APIs are protected against unauthorized access or DDoS attack, if the database is exposed to the internet, if the data on move and data on rest is properly encrypted, and so on. All of these concerns can be dealt with the proper allocation of cloud resources. Another significant concern is that the resource requirements vary between development, test, and staging environments. For a development environment, allocating all the resources can be a costly affair. Similarly, for testing and staging environments, we may need only a few of the resources. If IaC templates are crafted manually, it is likely that it will be a one-size-fits-all kind of template which may be inefficient and can lead to wastage of resources. Alternatively, it can morph into a generic, overcomplicated, and parametrized structure. So, despite the serverless breakthrough, we are still at square zero of DevOpsFinSec complexity dating from the previous century.
To sum up, the modern IaC stack is a patchwork reflecting the evolution of virtualization and cloud technologies incorporating at least three different concepts: traditional Infrastructure as a Service, elements of Platform as a Service, and Serverless Cloud.
There have been some attempts to alleviate the pain, but I would argue that none of them brings a satisfactory solution because I believe the root cause is yet to be analyzed. To understand the challenges with the IaC stack and what it means in practice, let’s look at Cloud IaC ingredients.
Cloud IaC Stack: Components and Relationships
To understand how to ideally implement the automatic allocation of serverless cloud application resources, we need to map existing components and their relationships. For this article, I will use a combination of AWS and Python back-end ecosystems. The real landscape map is too complex to be presented in one publication.
Let’s first look at AWS Serverless Ecosystem:
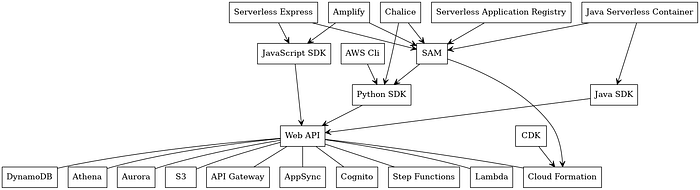
Core Cloud Services
At the bottom of the stack, there is an ever-growing list of AWS Cloud Services (over 200 at the moment). Each service exposes a REST API. Few services, such as AWS S3, are fully-managed and serverless, which means that you never need to deal directly with reserving and managing the capacity for these services. However, some services, such as AWS Aurora, have fully-managed serverless options (aka Aurora Serveless), but can also be operated via a traditional cluster configuration (AWS RDS in this case). Whereas, there are some other services, such as AWS Neptune and AWS OpenSearch which do not have a fully-managed serverless option at the moment, but might have in the future (AWS every year announces a slew of new serverless options). What is important to notice is that the cloud service REST APIs are the only 100% reliable source of truth about what these cloud services can or cannot do and announce authentic promises [9] of these services. Anything else built on top of these APIs is much less dependable.
Some cloud services, managed or not, have a 3rd party drop-in replacement (e.g. ElasticSearch, Cassandra, MongoDB), also managed or not. It complicates the whole picture even more. I won’t pursue this further in this article. However, any final solution would not be able to ignore this trend.
Cloud Orchestration Service
AWS CloudFormation is a unique service responsible for orchestrating the allocation of all resources from other services. To know about similar services from other cloud vendors, look at the references below.
All cloud orchestration tools derive their basic concepts from CFEngine but seldom did this in full scope and consistently. They allow specifying the cloud resource configuration in some form of declarative or semi-declarative style encoded as a JSON or YAML document. The cloud orchestration service takes this document and allocates, updates, or deletes resources to reach the desired final state with best efforts. By definition, cloud orchestration service makes only conditional promisses [9]. It can allocate a coordinated set of cloud resources only if underlying cloud services fulfill their promises. Usually, it works as intended. But at times, things fail between the cracks. In any case, there is usually a lag between core service capability made available and its support by the cloud orchestration service.
Also, it is important to notice that this cloud orchestration service does not distinguish between fully managed, partially managed, or unmanaged services. The same language is used for all the services and one template can contain an arbitrary mix of different types of services.
Originally conceived pure declarative style never worked well. So, AWS CloudFormation template language started introducing Parameters, Pseudo Parameters, Conditions, Intrinsic Functions, Custom Resources, Macros, Modules, Regular Expressions, Nested Stacks progressively in order to make CloudFormation templates more flexible and modular.
With regards to serverless, AWS CloudFormation template language has another serious drawback, and AWS SAM cosmetics (see below) did not address it. Since templates are manually crafted, there is a strong inclination to specify one Lambda Function per trigger (e.g., all HTTP requests). We human beings are energy-saving optimizers. There are even strong voices [21] arguing that this is the right way to do it. And this is seriously problematic. Firstly, different events coming from the same trigger, in general cases, require a different number of resources and processing timeout limits. Secondly, these events require different permissions and access to different resources (think about HTTP GET vs HTTP PUT). And thirdly, it might be beneficial to use different run-time versions or even different languages (e.g., for gradual upgrades or optimizations). True, we could, in principle, start with one monolithic Lambda Function and pull-out individual functions as needed. However, that is not the case usually. Also, no one can guarantee that it would be easy to extract specific functionality into a separate Lambda Function. Things that once have been clumped together usually resist separation.
Cloud Services SDK
Cloud orchestration services, such as AWS CloudFormation, are not the only way to access cloud services. Cloud service REST APIs are wrapped in language-specific SDK libraries. For accessing AWS services using Python, there are two types of interfaces: a low-level interface, botocore and a high-level interface, boto3.
As with the cloud orchestration service mentioned above, SDKs make conditional promises depending on the original REST APIs and can introduce a lag, usually small. Also, the capabilities vary with languages. E.g., Python and Go SDK capabilities may or may not be identical.
Needless to say, a cloud orchestration service has its own REST APIs wrapped with its own SDK.
Cloud CLI and Console
Other than cloud SDK, there are two additional ways to interact with the cloud services: via a Command Line Interface, such as aws cli and using the Management Console. Whether the latter is implemented on the top of some, say JavaScript SDK, is my wild guess (I do not know it for sure). But it seems to be a plausible assumption, as working directly with REST APIs can be cumbersome.
Addressing IaC challenges: Tools and Frameworks
IaC concept has its own challenges and problem areas. There have been many fraweworks and tools that have tried to reduce or address the IaC challenges to some extent.
Serverless Application Model (SAM) — nice try
Somebody within AWS realized quite early that the AWS CloudFormation template language is too complicated and too low-level for typical Serverless Applications and tried to solve the problem by introducing AWS Serverless Application Model (SAM). It came with a simplified SAM Template Language, SAM CLI and AWS Serverless Application Repository. On the client-side, it was combined with AWS Amplify Framework.
It was a nice try and many people used it, including yours sincerely, at least at the beginning. But IMHO, it did not and could not proceed too far. If AWS CloudFormation template language could be treated as Machine Code Language [10], then SAM Template Language could just be considered a macro-assembler for it. It does not provide enough abstraction and in fact, introduces leaky abstraction (it’s too easy to fail back on CF syntax). In short, it just allowed writing smaller JSON/YAML and did not address the core problem.
AWS Cloud Development Kit
As a typical American business, AWS is a large organization where different people keep trying their ideas. It looks like somebody within AWS (or they just acquired a startup) realized that irrespective of the tricks applied to JSON/YAML, it would never be as powerful as a mainstream programming language. Somebody came up with a strong preference to embed CloudFormation Domain Specific Language into a mainstream host that led them to launch the AWS Cloud Development Kit.
Initially, it was available in TypeScript. Later, support was available in Python and other languages too.
And indeed, in terms of flexibility, modularity, and test automation AWS Cloud Development Kit solved all the problems inherited by AWS CloudFormation template language without introducing yet another service — it generates CloudFormation templates under the hood. What I did not like about it was a very opinionated decision about how many CloudFormation Stacks are to be created, but that’s another story for another paper.
My biggest problem with AWS Cloud Development Kit is that it remains at the same level of abstraction, mixing serverless and non-serverless types of resources. In other words, it remains to be a CloudFormation macro-assembler, just embedded in TypeScript or Python. In principle, a pure serverless framework can be built on top of a basic CDK (like CDK SAM), but I would seriously question whether it’s worthwhile doing so. Macro-assembler will remain a macro-assembler anyways.
AWS Chalice
AWS Chalice was a half-step forward from IaC.
If all we want to do is to develop a bunch of AWS Lambda Functions to be triggered by various cloud events (e.g. an API Gateway HTTP Request), why not generate these functions directly from the Python (or whatever other languages) code? This reasoning is what stands behind the AWS Chalice Framework (another startup acquisition?) that we could classify as one of the early attempts to switch from Infrastructure as Code (IaC) to Infrastructure from Code (IfC).
AWS Chalice Framework uses Python Function Decorators for generating Lambda Functions attached to various triggers. It could deploy resulting service using Python SDK, CloudFormation, Terraform or AWS CDK.
As said above, it was a big half-step forward (pun intended). Why half-step? Because it swept a lot of traditional IaC garbage under a carpet of separate configuration file. It is not seen in the code, but some DevOps Engineer still needs to carefully craft this configuration file. At the bottom line, we stay with the same level of abstraction, just pushed a little bit further.
Personally, I’m not in favour of using Python Function Decorators for protocol and event trigger routing [11]. In my view, this obscures too much business logic and brings up many irrelevant low-level details of, say, HTTP protocol.
Vendor/platform locking is a more serious question to be addressed. If we start talking about IfC, should we also strive towards cloud platform neutrality, such that instead of s3_trigger we should talk about a cloud_storage_object_created trigger regardless of whether it is AWS S3 or GCP Cloud? Using a proper level of abstraction and liberating application developers from intricate details of the cloud platform is a strong argument in favour of cloud neutrality. (Multi-cloud and poly-cloud are different strategies and big topics to be addressed elsewhere). Danger to deteriorate to least-common-dominator mediocracy is a strong argument against it. I will come back to this in the last section.
3rd Party Serverless Ecosystem
AWS is not alone in its attempts to address cloud IaC challenges. Many 3rd party players, commercial or not, developed complementary or alternative solutions on top of AWS CloudFormation:
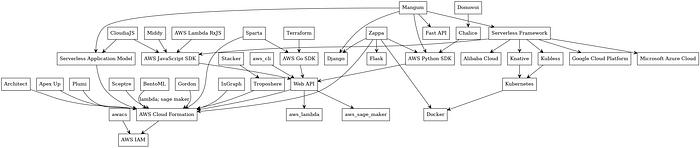
A few of these 3rd party vendors are listed below (look at references below for even more). Detailed analysis of each of them is far beyond the scope of this publication. I will bring in some general observations here:
- Serverless Framework continues the external macro-assembler DSL (shorter YAML, some cloud neutrality, but essentially the same level of abstraction)
- Pulumi, InGraph, and Troposphere continue the same line of embedded (in Python) macro-assembler DSL
- HashiCorp Terraform started as a macro-assembler external DSL, but now with its new Terraform CDK started switching to embedded DSL
- Zappa and Gordon (both seem to be not supported anymore) made a sincere effort to implement Infrastructure from Code for Python but did not proceed farther than AWS Chalice
- Domovoi is an interesting attempt to extend AWS Chalice to handle AWS Lambda event sources other than HTTP requests through API Gateway. It does this through Python decorators, thus mixing core application logic with infrastructure boilerplate and making it cloud platform dependent.
- Mangum is another interesting attempt to integrate PythonASGI applications built with popular frameworks such as Django and Fast API with AWS Lambda & API Gateway. As such, it might be useful for quick porting of existing Python applications to the serverless cloud while preserving cloud neutrality, but due to the lack of integration with cloud resource generation it leaves it to external IaC tools such as Serverless Framework or AWS Serverless Application Model (SAM)
Based on this brief analysis, it would be safe to conclude that none of the existing 3rd party serverless frameworks provide an adequate solution to implement Infrastructure from Code to its full extent.
Infrastructure from Code Needs: it does not hurt to dream!
Infrastructure from Code (IfC) requires changes in the existing technologies by the cloud vendors, programming language vendors, and tools & library vendors. Let’s look at the wish list for each of them one by one.
Cloud Platform Enhancements
This is not directly related to converting plain application code (in a programming language) into serverless cloud resources specifications. However, if implemented one day, it would dramatically simplify the whole task.
- Reduce cloud orchestration service promises scope: Core cloud services should take full responsibility for fulfilling their promises, leaving the cloud orchestration service to do what it’s supposed to do. It is especially important for so-called drift detection. Services should do this for themselves and reject any resource specification change request unless it comes from the resource owner. It’s funny and sad to think that CFEngine has been doing it for years and cloud services are still not there. With the recent introduction of AWS Control API, there is hope that things will move in the desired direction.
- Hide as many configuration details as possible: Do I need to specify how much RAM/vCPUs a function needs and how is it different from old generation capacity planning? What about automatic detection of the run-time environment? What about assisting with enforcing the Principle of Least Priviledge? The list of such questions is quite long. In theory, cloud vendors are in a position to do this. The big question is will they do it, and if yes, when?
Programming Language Enhancements
At the moment, no mainstream programming language provides a cloud-native run-time environment. New languages, such as Ballerina and Ecstasy might take a long time to be adopted by the developer community (software developers are very conservative). Tweaking existing mainstream languages to support cloud environments might be a better strategy:
- Cloud-native import system [31]: There is no essential reason to install anything on cloud. Ideally, all the open-source and commercial libraries should be available directly from the cloud storage.
- Automatic module digest calculation: With the cloud import system in place, there is a need to enforce cloud function cold start when something changes. Efficient calculation of digital signature for every method would be the most reliable way to achieve this.
- Extended library of standard protocols and abstract interfaces: This is required for automatic detection of the cloud resources to be allocated in different scenarios. For example, Python DB API specifies an exact protocol for database connection object, but there is no Python Protocol Class defined for it, which can be used to detect the cloud resources needed. Indeed, if an application defines that it will use a
db_connectionobject with MySQL query language dialect, Aurora Serverless for MySQL could be allocated automatically. - Enhanced compiler abstract tree support: In Python, ast does a pretty nascent job. More awareness from the language compiler vendors that code generator target could be a cloud resource [11] would help. PyPy made some progress in this area, but it’s still not mainstream and not easy to use.
Tools and Library Enhancements
- Proper support for cloud import system: Very often, it’s about following the language best practices, yet it’s seldom the case, especially tools’ reliance on the local file system is too limiting.
- Cloud-friendly build system: Building on the cloud for the cloud requires a different approach to dependency management and build task orchestration. Existing tools are inadequate in this respect and need to evolve.
Standardisation of Object-Cloud Resource Mapping
This topic fails somewhere between cloud platform, compiler, tools, and libraries vendors. To maintain cloud neutrality, there is a need to use standard interfaces as much as possible. For example, instead of relying on AWS SES, AWS SQS and AWS SNS arcane APIs, why not define a standard Channel Protocol with a send function and let the service specify whether it's a Queue, PubSub, Email or any composition of them? Such specification would be completely cloud-neutral and translatable into underlying cloud resources specification with a modest programming effort.
Another example would be translating standard data structure APIs, such as Python MutableMapping into cloud storage, SQL or NoSQL database resources. It may not work for cases that require some special optimization, but, in most cases, it will work just fine.
Lastly, what about access to cloud resources via standard interfaces? For example, why do I need to use AWS IAM arcane API to manipulate the list of users, roles, and policies rather than to use the same Python MutableMapping with different return value types?
Who should implement such mappings is unclear at the moment. Ideally, cloud service vendors in cooperation with language compiler vendors should take care of it. In reality, it would be a community-driven open project bringing together multiple players who think this is the right thing to do to boost cloud application development productivity and quality.
Serverless IDE
In the serverless and Infrastructure from Code world, it gets progressively harder to justify traditional Integrated Development Environment systems running on local computers or cloud virtual machines. Indeed, modern browsers are powerful enough to run a decent editor inside, while it should be possible to build a serverless backend for storage, computing, IntelliSense, etc. Why should I clone it from git to my local disk to later upload it to cloud storage? Why can’t cloud storage do the whole job? Why can’t I run my unit or integrated tests in Cloud Function? Why Language Server Protocol cannot be implemented by another set of Cloud Functions via WebSockets or REST API?
A short answer to these questions is: “it is all feasible and within reach too.” We do not have the tools yet, although, they were conceptually demonstrated in 1968 at The Mother of All Demos. Software development is merely a slightly special kind of knowledge work. Therefore, Integrated Software Development System is supposed to be just a variant of Augmented Knowledge Workshop. After many years of trial and error, exacerbated by greed and ambition as major drivers of high-tech industry, can we hope to leverage the virtually unlimited power of modern clouds and realize the vision conceived so many years ago and naturally required by common sense?
The New Wave of IfC
Recently, a number of solutions have come up which are trying to promote Infrastructure from Code concepts, at times under different names.
- CAIOS, the Cloud AI Operating System: as benchmarked up to 10x improvements in developer productivity and deployment speed using its IfC technology versus traditional DevOps processes. It also addresses performance optimization and security best practices to some extent as part of IfC. CAIOS currently supports Python development and deployment on AWS. Disclaimer: The author of this article works for BST LABS (a unit of BlackSwan Technologies), the creator of CAIOS.
- Serverless Cloud: probably the most known, documented and advanced offering supporting JavaScript and TypeScript
- Lambdragon: positions itself as a next-generation cloud IDE for JavaScript and TypeScript
- Encore: a backend development framework in Golang that simplifies calling APIs as functions.
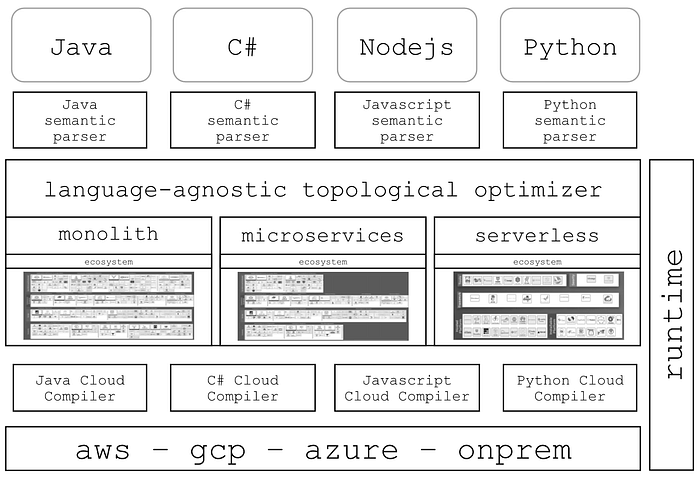
- CloudCompiler: This one speaks along the lines outlined above (see diagram below). It is still in private beta and not enough details are available yet (the site has not been updated since 2020).
Summing-Up
The serverless world is a fast-moving space where Infrastructure from Code is the next advance that can make it move even faster. The history and evolution of cloud technologies and the challenges with the current technologies presented above clearly indicate the likelihood of maturation of IfC in the coming years. IfC has the potential to optimize and bring much-needed gains in agility to cloud applications.
The author, Asher Sterkin, is GM at BST LABS. BST LABS is breaking the cloud barrier — making it easier for organizations to realize the full potential of cloud computing through a range of open source and commercial offerings. We are best known for CAIOS, the Cloud AI Operating System, a development platform featuring Infrastructure-from-Code technology. BST LABS is a software engineering unit of BlackSwan Technologies.
References
- S. Wardley, “Evolution begets Genesis begets Evolution”
- S. Wardley, “Everything Evolves”
- M. Burgess, “Semantic Spacetimes Project”
- Just Enough Developed Infrastructure: Devops Areas — Codifying devops practices
- Simon Wardley, “Why the fuss about serverless”
- How serverless impacts design — Gojko Adzic — DDD Europe 2020
- G. Adzic, Serverless architectures: game-changer or a recycled fad?
- G. Adzic, Designing for the Serverless Age
- M. Burgess, “Promise Theory: Principles and Applications”
- A. Sterkin, “If your Computer is the Cloud, what should its Operating System look like?”
- A. Sterkin, “Cloud Service Template Compiler in Python”
- Sceptre
- Troposphere
- Stacker
- awacs
- Pulumi
- Serverless Framework
- B. Kehoe Infrastructure as Code on AWS in a familiar language — the right way with InGraph
- Yan Cui, 24 open source tools for the serverless developer: Part 1
- Yan Cui, 24 open source tools for the serverless developer: Part 2
- Yan Cui, LAMBDA DEPLOYMENT FRAMEWORKS COMPARED
- Yan Cui, AWS Lambda — should you have few monolithic functions or many single-purposed functions?
- HashiCorp Terraform
- Azure Resource Manager
- Google Cloud Deployment Manager
- Devops with the S for Sharing — Patrick Debois, Jax 2012, London
- Patrick Debois — From Serverless to Servicefull, ServerlessConf NYC 2016
- Working on DevSecOps culture — a team centric view — Patric Debois
- It’s code but not as we know: Infrastructure as Code — Patrick Debois, Jax 2012, London
- Adrian Cockcroft, “Trends and Topics for 2022”
- A. Sterkin, “Serverless Cloud Import System
