AWS MAPU
Multiple AWS Accounts/Platforms/Users Environment

This report marks my first serious foray into substantial use of Generative AI tools for non-trivial cloud solution architecture. I experimented with other tools like Perplexity, Claude, and Bard, but, with rare exceptions, they fell short of ChatGPT’s results by a significant margin. Thus, this project — and the resulting technical report — represent my first serious endeavor of co-authoring with ChatGPT. It’s worth mentioning that the opening image was generated using the DALL·E 3 tool.
For those who are curious and eager to get straight to the bottom line, allow me to summarize my experience in a single paragraph:
Generative AI can serve as a brainstorming partner, a source of information on unfamiliar topics, and a tool for generating images when you have a clear theme in mind. It can also handle some mundane yet complex technical tasks, such as drafting initial versions of AWS IAM Policies, CloudFormation JSON, or Python or Bash scripts. However, it cannot think for you, connect the dots, validate the overall coherence of your system-wide architectural decisions, or possess common sense or a sense of humor. Consistency in responses should not be expected. In short, Generative AI can be a highly useful and powerful statistical tool if you know what you aim to achieve. Relying solely on Prompt Engineering will not shield you from errors.
Disclaimer
Due to various personal and business considerations, the developed solution is not Open Source and may not be fully prepared for production use. Currently, it adequately meets my requirements as a software technology researcher but does not extend beyond that scope. In this report, I will outline the fundamental needs addressed by this project (which may align with or differ from your own) and the overarching system architecture. However, I will not provide source code details. For further technical information, please contact me directly.
Background and Initial Requirements
My journey began while preparing to publish my initial findings on the Winglang programming language. The initial task was straightforward: installing the language toolkit, but the choice of where posed a challenge.
As a software technology researcher who frequently experiments with various programming languages, runtimes, and cloud platforms, I maintain a minimal setup on my workstations. Their transient nature and frequent replacements make them unworthy for serious installations. Consequently, for nearly a decade, my work has predominantly been conducted on virtual desktops hosted in the cloud.
In previous roles within large organizations, launching a VM on the corporate cloud and connecting via SSH was straightforward. Leading a development team, I extended this approach to the entire group, utilizing corporate cloud resources under the IT department’s management.
Now, as an independent researcher, I faced a need to evaluate several less-than-ideal options:
- Assume full system administration responsibilities.
- Rely on a home computer, possibly with local virtualization like Oracle Virtual Box.
- Explore hosted solutions, such as GitHub Gitpod.
- Consider cloud Web IDEs, like Cloud9.
- Operate exclusively in Cloud Shell using Vim or a similar text-based editor.
- Contemplate finding a new job where access to a corporate cloud and basic administrative support are available.
Assuming full administrative responsibilities initially seemed daunting: I am not an experienced sysadmin, and it did not directly align with my primary task.
I have a personal AWS account set up a few years back, which, despite being somewhat disorganized, costs less than $2 monthly and has not been a major concern. Yet, I was reluctant to use it for new projects.
My additional considerations were:
- I conduct software technology research for various prospects and my own needs. I aim to keep these projects separate for cost control and basic security reasons.
- I must be economical with my expenses and closely manage cloud costs. A past oversight resulted in charges tenfold of what I had anticipated.
- Cloud technologies are rapidly evolving, and I wanted firsthand experience with them without incurring significant risks.
These factors prompted extensive discussions with ChatGPT to brainstorm cloud self-administration options. Although ChatGPT couldn’t make decisions for me — and sometimes even commended questionable ideas — articulating my thoughts, weighing pros and cons, and accessing external information without delving into lengthy and poorly written technical documents proved invaluable.
Imagine a conversation partner who may not be exceptionally insightful but is always available, supportive, and infinitely patient. This was beneficial, and I devised a solution meeting my current needs with potential for future growth and a practical opportunity to learn about cloud technologies.
The construction of the final system and the rationale behind each architectural decision will be discussed in the next section. The concluding section will address some limitations of the current version and potential research directions.
A crucial insight from this endeavor was:
Charging cloud solution architects for the costs of the systems they design could dramatically alter their way of thinking.
About System Diagrams
Cloud solution architects often prefer creating visual representations, which they proudly refer to as system diagrams, over writing documents. However, these diagrams frequently lack consistent semantics. My early critiques on the poor state of cloud architecture diagrams can be found here, and regrettably, little has improved since then. The two primary issues are:
- Lines: The meanings of arrowheads and directions vary, inconsistently indicating control flow, data flow, visibility (reference), or distinguishing between permanent and transient connections. Most diagrams I’ve encountered mix these meanings.
- Boxes: It’s often unclear whether they represent a specific cloud service or a cloud resource. The situation is exacerbated by cloud vendors like AWS, which either lack icons for many of their resources or use icons that are inconsistently applied and confusing.
The root of these problems may lie in the Model-Driven Architecture and the Unified Modeling Language. The initial idea was that, similar to other engineering disciplines that use blueprints, software engineering should too. However, software encompasses a complex, multi-dimensional time-space structure that generally cannot be accurately depicted on a two-dimensional plane.
The prevailing practice involves architects drawing these diagrams, impressing and obtaining approval from clients who likely do not grasp the details, before handing the designs over to DevOps teams to implement. When designs change due to feedback or identified mistakes, these diagrams are seldom updated, leading to a significant disconnect between the initial concept and the final solution.
In my experience, I have rarely seen a non-trivial system developed from start to finish based solely on diagrams. Initial ideas might be sketched graphically on a napkin or whiteboard, but this practice is diminishing, partly due to the rise of remote work and partly because diagrams for complex systems become cluttered quickly.
My current workflow involves:
- Starting a conversation with ChatGPT about an initial idea.
- Exploring multiple options through text, which is faster and more natural as we think in words, not pictures.
- Requesting ChatGPT to generate initial code/test skeletons or final versions.
- Testing the output in an editor, running it, and observing the outcomes.
- Repeating the process until the system functions as intended.
- Documenting the system architecture in diagrams with limited detail but strong semantic consistency in the meanings of lines and boxes.
- Describing the diagram in text and revisiting step 1 for any significant flaws detected.
This technical report documents my system development process through conversations with ChatGPT, utilizing Vim, VSCode, and Make. I have yet to employ a co-pilot for such projects, leaving its utility as a topic for future exploration.
Ideally, an AI-empowered graphical tool with reliable round-trip support would greatly benefit the development process, but I’m not aware of any existing tools capable of this.
To ensure clarity and prevent misunderstandings in this report’s diagrams, I applied simple rules:
- Lines:
- Diamond heads indicate containment, e.g., VSCode installed on my local workstation.
- Open arrowheads represent visibility or reference. While distinguishing between permanent and temporary references with solid and dashed lines was considered, I opted against it to avoid unnecessary complexity. - Boxes:
- Icons represent cloud resources wherever possible.
- In cases where resource icons are unavailable or communication is directly with a cloud service (e.g., retrieving a secret), cloud service or third-party icons (e.g., GitHub) are used.
These guidelines aim to minimize potential confusion and ensure that the diagrams are as informative and accurate as possible.
System Overview
The structure of the overall system accounts and account-level permissions is depicted in the diagram below. This visualization aids in understanding the hierarchical organization and the distribution of permissions across different accounts, ensuring both security and functionality are maintained.
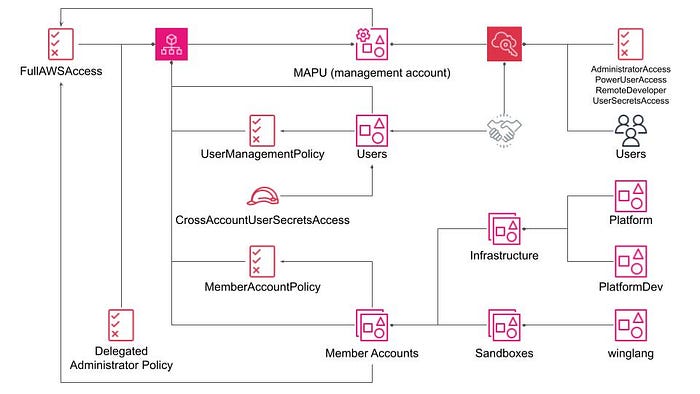
Let’s delve into a more detailed description of each element depicted in the diagram above:
- MAPU (Management Account): This is the root AWS Account from which everything originates. It houses an AWS Organization (on the left) and AWS Identity Center (on the right), with everything else managed by this trio. The complexity of AWS’s Multiple Accounts/Multiple Users management structure is indeed high and things are not always consistent.
- According to AWS best practices, the Management Account should be accessed as infrequently as possible, primarily for managing other accounts through the AWS Organization and, sometimes, the AWS Identity Center services.
- Within the AWS Organization service, we define other Accounts, Organization Units, Service Control Policies, and Delegated Administrator Policies.
- Service Control Policies (SCPs): These are used to define the maximum permissions for Accounts and/or Organization Units. In this system, we have three SCPs:
- FullAWSAccess: No effective restrictions.
- MemberAccountPolicy: Prevents member accounts from creating their own AWS Identity Center instances.
- UserManagementPolicy: A restricted set of permissions for managing users in the delegated administrator account Users, but not more. - Delegated Administrator Policy: Specifies what operations other, non-management, accounts can perform at the organization level, such as retrieving a list of accounts or an account name.
- To group all member accounts together and attach to them a combination of FullAWSAccess and MemberAccountPolicy SCPs (effectively preventing them from creating their own instance of the AWS Identity Center), we define one top-level Organization Unit, namely MemberAccounts.
- To separate accounts involved in actual software technology research and the development and operation of the whole system infrastructure, we define two second-level Organization Units:
- Infrastructure OU, currently with two accounts: Platform (production) and PlatformDev (development).
- Sandboxes OU, currently with one winglang account for technology research on the Winglang programming language. - Within the AWS Identity Center, we define a delegated administrator account (called Users) to grant it full permissions for user management, and four permission sets:
- AdministratorAccess: A full set of permissions, restricted, of course, by the Service Control Policy attached to the account.
- PowerUserAccess: A full set of permissions, restricted by SCP, for all services except for AWS IAM; intended for console access by non-administrator users.
- RemoteDeveloper: A restricted set of permissions for accessing AWS EC2 remote desktop Virtual Machine instances over AWS SSM connection.
- UserSecretsAccess: A restricted set of permissions for non-administrator users to manage their secrets within the Users account.
This configuration might seem overly complicated. To grasp the rationale behind it, we need to explore the details of how individual accounts are organized.
The winglang Account
The winglang account structure and typical configuration are depicted in the diagram below:

Let’s try to unpack the process and infrastructure laid out here:
- The end-user, in this case,
asher-sterkin, primarily operates within the VSCode IDE environment, avoiding direct interaction with the complexity depicted on the diagram. However, beneath the surface, the setup is quite sophisticated. - As noted initially, the installation on my local machine is deliberately minimal, comprising:
- VSCode IDE
- AWS CLI
- AWS CLI Session Manager Plugin
- A bash script to initiate SSH sessions over AWS SSM
- A~/.ssh/configfile configured for each remote desktop - In practice, the local VSCode IDE utilizes the Remote SSH Plugin to connect to a VSCode Remote Server, with the SSH session facilitated by an AWS SSM session.
- Moreover, the SSH configuration’s bash script interacts with the AWS EC2 Service to identify the EC2 VM Instance by its Name tag and initiate it if inactive. By convention, the VM instance’s Name tag matches the name of the enclosing AWS CloudFormation Stack, in this instance,
asher-sterkin-t4g-large-desktop(discussion on naming conventions to follow). - The EC2 VM Instance is allocated within an AWS CloudFormation Stack named
generic-desktop-vm, which nests within the<user-name>-<instance-type>-<instance-size>-<purpose>stack. - This EC2 VM instance resides within a specially configured security group of the default AWS Virtual Private Cloud, which blocks all incoming traffic, effectively isolating the VM from the internet and enabling communication solely through SSM tunneling.
- It is also linked to an EC2 VM Instance Profile Role, which, along with specific additions, grants it the PowerUser permissions previously discussed.
- Both the security group and the VM profile are defined in a separate AWS CloudFormation Stack, conventionally named
dev-platform. This structure makes possible the creation of multiple VM instances with identical security definitions within the same account (and region). - Both stacks originate from AWS CloudFormation Templates stored in an AWS S3 Bucket, traditionally named
<organization-id>-platform. This naming convention is necessary because AWS S3 bucket names must be globally unique.
Before delving into the rationale behind this architectural decision, it’s crucial to examine more closely how the generic-vm-instance stack is organized, how temporal session credentials are obtained, and which role is played by the Users account and its secrets.
Generic VM Instance Stack
The inner structure of the generic-vm-instance stack is presented below.
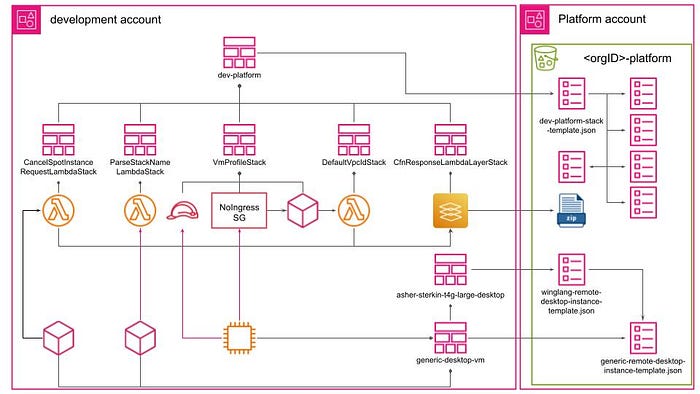
As previously discussed, the remote desktop VM instance is linked to a No Ingress Security Group within the Default VPC and to a VM Profile Role with permissions nearly equivalent to those of a PowerUser. We also noted that the VM’s Name tag mirrors the name of its parent stack, in this case, asher-sterkin-t4g-large-desktop.
A similar approach is taken for another User tag, which matches the user name, here asher-sterkin.
This explanation allows us to understand the implementation of this connection, specifically that the account-level dev-platform stack implements a number of AWS CloudFormation Custom Resources, each powered by its own Lambda Function. In detail:
- The Default VPC Id is retrieved by the DefaultVpcId custom resource.
- The User name, AWS EC2 image, architecture, and instance type are derived from the parent stack name by the ParseStackName custom resource (which also verifies the existence of the specified user in the system).
- If the VM instance is provisioned as an EC2 Spot Instance, an additional CancelSpotInstanceRequest custom resource is generated to cancel the spot instance request upon the instance’s termination (a task AWS does not automatically perform, potentially incurring significant costs if overlooked).
- All custom resources are required to signal to AWS CloudFormation upon completing a Create/Update/Delete request via the special
cfn-responseprotocol. To adapt this protocol to provide the diagnostics I needed instead of the default implementation, I incorporated its functionality into the CfnResponse Lambda Layer. - The templates for nested stacks and the zip file for the Lambda Layer are stored on the Platform S3 bucket.
The system is set up so that users can connect only to their VM instances by matching the user name tag of temporary credentials with the VM instance’s User tag, enforced by the RemoteDevelop policy. The process for acquiring these temporary session credentials and the mechanism for carrying over the user name involves two key components:
- The AWS CLI Single Sign-On configuration enables users to authenticate and receive session credentials. When attempting to connect to a remote desktop, the AWS CLI initially checks for locally cached valid session credentials. If such credentials are absent, it redirects the user to the AWS Single Sign-On login screen as specified in the AWS CLI profile. Here, the user must enter their password and, if enabled, a Multi-Factor Authentication (MFA) passcode.
- The AWS Identity Center keeps mappings between users, accounts and permission sets the users could use. It also defines which User Attributes for Access Control are carried over as a part of the session data.
This approach ensures that access is securely controlled and directly tied to individual user credentials and their respective permissions, as defined within the AWS Identity Center.
The capability to automatically detect the user name facilitates addressing another challenge: the automatic and secure retrieval of Git repository credentials within EC2 VM instances. This sophisticated mechanism warrants a detailed discussion in its own dedicated section.
Git Repository Credentials
In the cloud, remote desktop VM instances are ephemeral; they come and go — at least, that’s been my experience. Therefore, I don’t rely on VM local disks or mountable EBS or EFS to safeguard my source code artifacts. Instead, I push everything to a Git hosting service. But which one to choose?
AWS, like all other leading cloud vendors, offers its own fully managed Git hosting service, AWS CodeCommit. Opinions on CodeCommit are polarized: some, particularly those in SecOps, love it, while many developers vehemently oppose it, leaving few with a neutral, pragmatic attitude.
From the perspectives of security and operational convenience, AWS CodeCommit has some clear advantages. It allows automatic user authentication by configuring the Git credential helper to invoke !aws codecommit credential-helper $@, thus utilizing AWS Credentials for Git host service authentication—eliminating the need for a username/password or SSH Key. With some effort, this setup can even support cross-account access, as detailed in AWS's documentation. If the code is meant to remain within the company and the company plans to stay with AWS indefinitely, it’s a perfectly valid choice.
The challenge arises when a company, team, or I myself need to develop an Open Source project or use the same code base across multiple cloud platforms. While it’s theoretically possible with a cloud-managed Git hosting service, most developers prefer using a third-party hosting service like GitHub or GitLab. These platforms offer multiple options for user authentication:
- Username and password, possibly integrated with SAML Single Sign-On
- Passkey
- SSH Private/Public Key
- Personal Access Token
Entering my username and password or passcode each time I need to pull or push to a GitHub repository is not something I want to do. The SAML Single Sign-On option seems available only for GitHub Enterprise. The only two feasible options for me were SSH Key or Personal Access Token.
For many years, I’ve worked with SSH Keys, enduring the hassle and frustration of generating a Public/Private Key pair and configuring it in GitHub for each new VM. This time, after extensive discussions with ChatGPT, I’ve decided to explore the Personal Access Token option, resulting in the following design for centralized user secrets management:
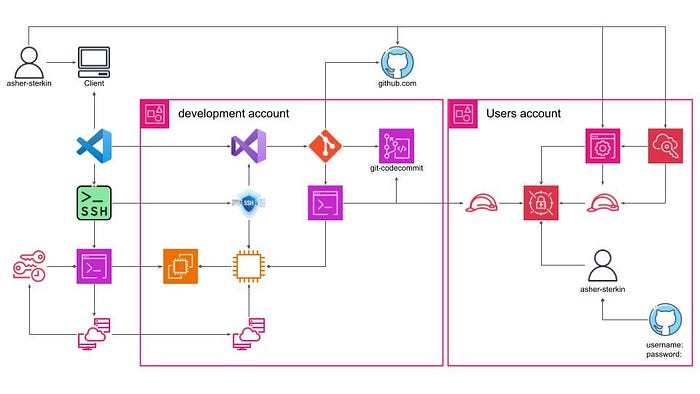
The security mechanism outlined above works as follows:
- Initially, the user configures a Personal Access Token within a Git hosting service, e.g., GitHub.
- The user then logs in via the AWS Identity Center login console into the Users account with a UsersSecretsAccess role, which allows users to manage secrets with a
<user-name>/prefix. - When the user wishes to perform a git pull or push operation, the git credential helper analyzes the repository URL. It then retrieves credentials directly from AWS CodeCommit or assumes the CrossAccountSecretsAccess role within the Users account to retrieve the username and password from AWS Secrets Manager.
- With the obtained credentials, the git client proceeds to access the required repository.
PlatformDev Account: Eating My Own Dogfood
In my personal life, I’m responsible for two pet dogs and we keep our plates and cuisine separate. However, I fully adhere to the “Eat Your Own Dog Food” approach as a principle in software architecture. My rule is very straightforward:
If you do not build your system with itself, you have no proof at hand.
The system architecture presented in previous sections involves developing some non-trivial code. For reasons of personal preference and to achieve results quickly, I opted for a combination of programming languages I am currently most fluent in: Bash and Python. This choice is not set in stone, and I might extend or altogether change the toolset in future versions.
This code needs to be developed, tested, and packaged somewhere. By applying the EYODF principle, creating a separate MAPU Platform account for MAPU Platform Development was the only option in line with professional ethics. This is the purpose of the PlatformDev account. With some minor modifications, its structure is practically identical to that of a normal development account, such as winglang:
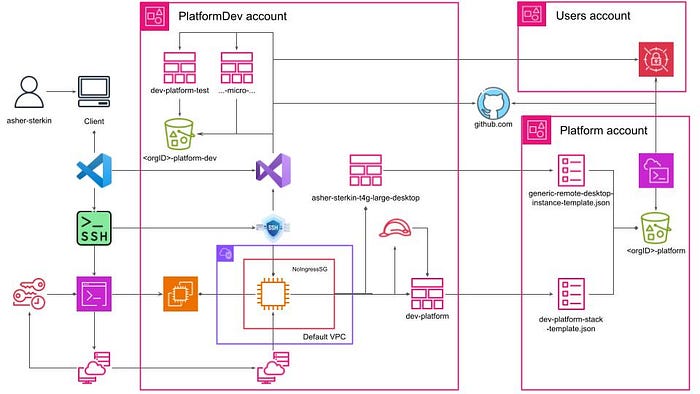
As shown, the PlatformDev account is organized in the same way as any development account, including secrets management for GitHub access.
It goes a step further by replicating the entire Platform account structure locally for testing purposes.
The Platform production account pulls infrastructure code artifacts from GitHub (using the same security mechanism, mind you) and builds and deploys the system from AWS Cloud Shell.
This structure opens up some interesting perspectives for a fully automated CI/CD pipeline to be explored in the future.
As mentioned, the PlatformDev account uses the generic desktop template. It’s probably a good time to explain what differentiates it, specifically the User Data scripts.
Different development platforms require different prerequisites to be installed on a remote desktop. For example, Winglang requires npm and terraform to be installed and configured. Since the MAPU Platform is currently developed in Bash and Python, it does not need them. I was also unprepared to create a common Python template but might do so in the future.
However, all platforms have several things in common, specifically:
- AWS CLI must be properly configured.
- Common tools such as make and git client should be installed.
- A special Bash script implementing the git credential helper discussed above should be stored on the disk, and git should be configured accordingly to use it.
- In addition, a Bash script responsible for shutting down inactive VM instances should be stored on disk and scheduled.
- Finally, the CloudFormation service must be properly signaled that EC2 VM instance customization has finished.
All these boilerplate activities are implemented within the generic desktop User Data. More platform-specific templates will just need to provide their additional installation and configuration scripts.
Concluding Remarks
Developing a non-trivial cloud infrastructure solution with the close assistance of Generative AI tools, primarily ChatGPT, has been an intriguing and enlightening journey. Specifically, initial versions of many AWS CloudFormation templates, policy JSON files, Bash scripts, and Python tests and implementations were produced by ChatGPT and refined later. However, the process was not without its challenges and required diligent supervision on my part. Thus, one should not expect Generative AI to fully automate tasks beyond their own capabilities — not just yet, at least. While it can save time, there’s also the risk of misinterpretation and errors.
From the perspective of system functionality, I am quite satisfied with the outcomes. The system meets my current needs effectively. Yet, there are areas for future exploration and enhancement:
- System Update Automation: This remains a critical challenge in any system, especially in infrastructure automation. CI/CD, while appealing in concept, hides complexity in its details. Currently, the system is stable, and managing a limited number of accounts, stacks, and VM instances manually is acceptable. However, should the system expand significantly — a testament to its success — automation of updates will become a priority.
- Relying on SSH for VSCode Server: This topic is contentious. Strictly speaking, leveraging SSH for port redirection, which AWS SSM could directly handle, introduces unnecessary complexity. My current approach, involving the generation of a temporary SSH key and its transfer to the VM instance via SSM Send Command, poses security concerns. Moreover, enabling generic SSH access could expose security vulnerabilities if my desktop were compromised. An alternative could be to restrict SSM Send Command usage and, for terminal activities, rely on SSM Sessions. While not an immediate concern, it presents a valuable avenue for future investigation.
- Desktop vs. Web Interface: The current setup necessitates specific prerequisites on the client workstation, which, while manageable on my personal Ubuntu MATE Desktop, could become a significant support issue on a larger scale across different operating systems. Web-based IDEs like Coder offer potential solutions but come with their own set of network security and plugin limitations. Past experiments with AWS Appstream and Ubuntu MATE Desktop on AWS EC2 via XRDP Protocol addressed some issues but introduced others, such as bandwidth consumption, configuration complexity, and unresolved network security challenges. This area, while not immediately critical, poses an interesting challenge for future exploration.
- User Resources Protection and Sharing: Currently, the system ensures the security of individual user remote desktop instances by allowing only the user with the corresponding username access. However, this does not prevent users from manipulating each other’s cloud resources via the AWS Console, as all are granted PowerUser privileges and could, in theory, do anything they wish. To achieve such a level of protection, the system would need to tag every cloud resource with the username, but implementing such protection universally is challenging. Additionally, the current setup does not facilitate controlled sharing of access to remote desktops between users, akin to the functionality offered by AWS Cloud9. Both topics warrant further investigation.
- Using Advanced AWS Services and Solutions: In this project, I utilized AWS Organization and AWS Identity Center to construct a basic multi-account and multi-user solution. I deferred the exploration of more advanced services and solutions, such as AWS Control Tower, AWS Landing Zone Accellerator, Service Workbench on AWS, Research Service Workbench on AWS and AWS Sandbox Accounts for Events, to future projects.
In conclusion, as I mentioned at the outset, the system is not currently open source. If you’re interested in a more focused discussion, please feel free to reach out.
